3 minutes
How to deal with missing values?

Missing data can happen in an unorganized raw dataset when no information is given for one or multiple items. There are various reasons behind this. Sometimes people just feel uncomfortable to share certain kind of personal information in a survey. Other times, the data collector may simply forget to input one number. Dealing with missing data is crucial in data science. Trust me, you will feel frustrated when you click the “run” button to train your hard built machine learning model and get an “MissingValueError” response from Python.
There is a module called “Pandas” in Python can help us taking care of this issue (Can anyone tell me in comment why the developers gave it such a cute name?). It is a must learn module for every data scientist because of its efficiency in processing large datasets.
In Pandas, missing data is mainly represented by NaN (Not a Number), a special floating-point value recognized by all systems that use the standard IEEE floating-point representation.
There are several functions in Pandas dataframe that can help us:
isnull() and notnull():
Both function help in checking whether a value is NaN or not. These function can also be used in Pandas Series in order to find null values in a series.
missing_income = pd.isnull(data['income'])
#isnull() return dataframe of Boolean values which are True for NaN values
income = pd.notnull(data['income'])
#notnull() return dataframe of Boolean values which are False for NaN values
dropna():
This function provides different mathods to drop rows/columns of datasets that have NaN values.
For example, it can drop rows with at least one NaN value: df.dropna(). Or it can drop rows which all values are missing: df.dropna(how ='all'). If you want to drop columns that ave at least one NaN value: df.dropna(axis=1) (Normally not an optimized solution). Check this documentation for details.
replace(),fillna() and interpolate():
These three functions substitute NaN value with a value given by themselves. For example: df.fillna(0) will replace all NaN with a 0 or any number given in the parentheses. df.fillna(mathod='pad')will fill NaN with the previous value.
The use of replace() is more general. Literally, it can replace any value in a dataframe. Here, if we want to replace NaN values, we have to use this form: df.replace(to_replace = np.nan, value = 0).Click here for more information.
interpolate() is more like give a method to Pandas so it can compute a value to replace the NaN value. For example: df.interpolate(method ='linear', limit_direction ='forward') will use a forward oriented linear function to compute a value and use it to replace the missing value. Beside the default setting linear method, there are other methods that can fulfill our needs, such as polynomial, cubic, spline etc,. For more details about this function, feel free to click here
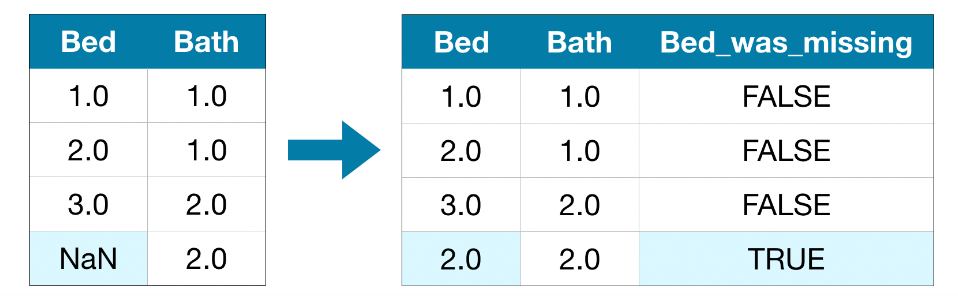
Choosing the right function to process missing values is crucial for the success of any kind of data science task. Don’t drop any NaN blindfolded. Think carefully, if possible, find reasons to explain why the value is missing. It could be a feature that not match for a certain observation. In this case, replacing the NaN with the mean value then creating a new column to indicate the status of missing value is more likely a better solution.